Big Data Concepts Storage
Overview of Hadoop Tools and Concepts - Storage
- Table of contents
- Storage
- SQL on hadoop
Table of contents
- Table of contents
- Storage
- SQL on hadoop
Storage
HDFS
Architecture
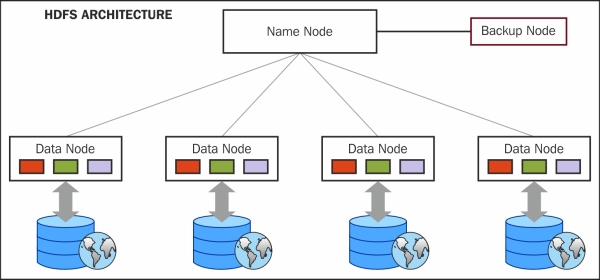
Datanode

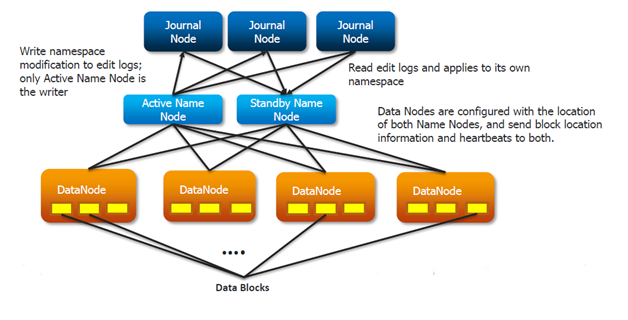
Journalnodes
In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called “JournalNodes”.
- Active node logs namespace modification to majority of JNs.
- Standby node can read edits from JNs and is constantly watching for changes in edit log
Read Path

- The client using a Distributed FileSystem object of Hadoop client API calls open() which initiate the read request.
- Distributed FileSystem connects with NameNode. NameNode identifies the block locations of the file to be read and in which DataNodes the block is located.
- NameNode then sends the list of DataNodes in order of nearest DataNodes from the client.
- Distributed FileSystem then creates FSDataInputStream objects, which, in turn, wrap a DFSInputStream, which can connect to the DataNodes selected and get the block, and return to the client. The client initiates the transfer by calling the read() of FSDataInputStream.
- FSDataInputStream repeatedly calls the read() method to get the block data.
- When the end of the block is reached, DFSInputStream closes the connection from the DataNode and identifies the best DataNode for the next block.
- When the client has finished reading, it will call close() on FSDataInputStream to close the connection.
Write Path

- The client, using a Distributed FileSystem object of Hadoop client API, calls create(), which initiates the write request.
- Distributed FileSystem connects with NameNode. NameNode initiates a new file creation, and creates a new record in metadata and initiates an output stream of type FSDataOutputStream, which wraps DFSOutputStream and returns it to the client. Before initiating the file creation, NameNode checks if a file already exists and whether the client has permissions to create a new file and if any of the condition is true then an IOException is thrown to the client.
- The client uses the FSDataOutputStream object to write the data and calls the write() method. The FSDataOutputStream object, which is DFSOutputStream, handles the communication with the DataNodes and NameNode.
- DFSOutputStream splits files to blocks and coordinates with NameNode to identify the DataNode and the replica DataNodes. The number of the replication factor will be the number of DataNodes identified. Data will be sent to a DataNode in packets, and that DataNode will send the same packet to the second DataNode, the second DataNode will send it to the third, and so on, until the number of DataNodes is identified.
- When all the packets are received and written, DataNodes send an acknowledgement packet to the sender DataNode, to the client. DFSOutputStream maintains a queue internally to check if the packets are successfully written by DataNode. DFSOutputStream also handles if the acknowledgment is not received or DataNode fails while writing.
- If all the packets have been successfully written, then the client closes the stream.
- If the process is completed, then the Distributed FileSystem object notifies the NameNode of the status.
HDFS federation

Active/passive Namenode
- Active Namenode is the one who is writing edits to JournalNodes.
- DataNodes know about location of both Namenodes, they send block location information and heartbeats to both.
- Passive Namenode performs checkpoints (of namespace state), no Secondary NameNode required.
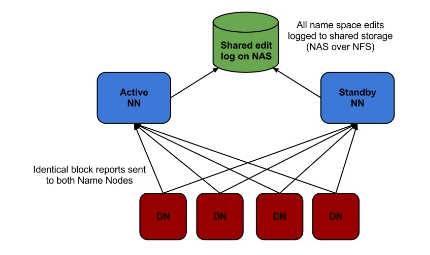
High availability
In general, there are two approaches
- Shared Storage using NFS
- Quorum-based Storage
Shared Storage using NFS

Quorum-based Storage

adds two new components to HDFS deployment
- Zookeeper quorum
- ZKFailoverController (ZKFC)
Automatic failover relies on Zookeeper:
- Each Namenode maintains persistent session in Zookeeper
- If machine crashes, session expires
- Other Namenode is notified to take over
ZKFC is responsible for:
- ZKFC pings its local Namenode. If unresponsive, ZKFC marks it as unhealthy.
NoSQL
Concepts
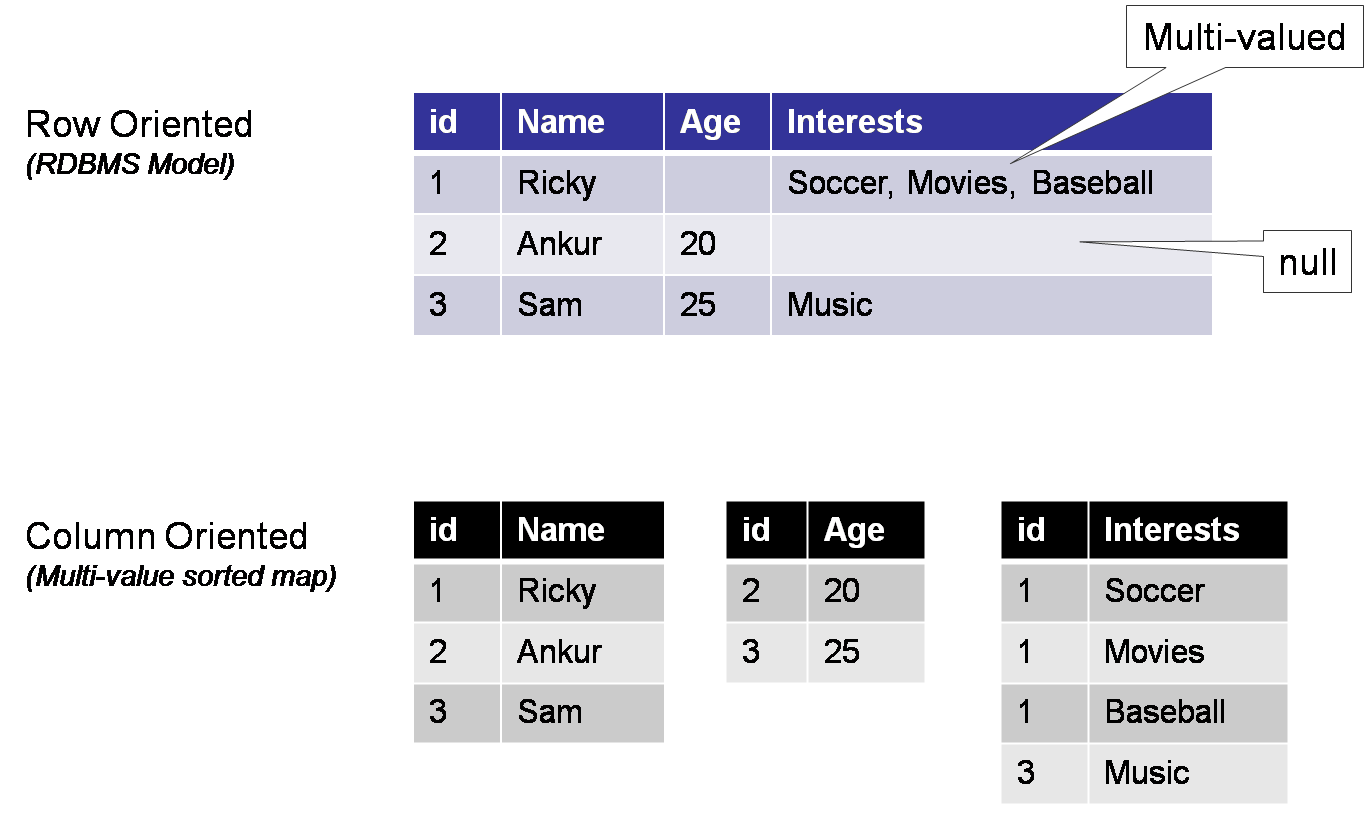
Row- vs. column-oriented

HBase
Overview
- Sparse: HBase is columnar and partition oriented. Usually, a record may have many columns and many of them may have null data, or the values may be repeated. HBase can efficiently and effectively save the space in sparse data.
- Distributed: Data is stored in multiple nodes, scattered across the cluster.
- Persistent: Data is written and saved in the cluster.
- Multidimensional: A row can have multiple versions or timestamps of values.
- Map: Key-Value Pair links the data structure to store the data.
- Sorted: The Key in the structure is stored in a sorted order for faster read and write optimization.
Advantages
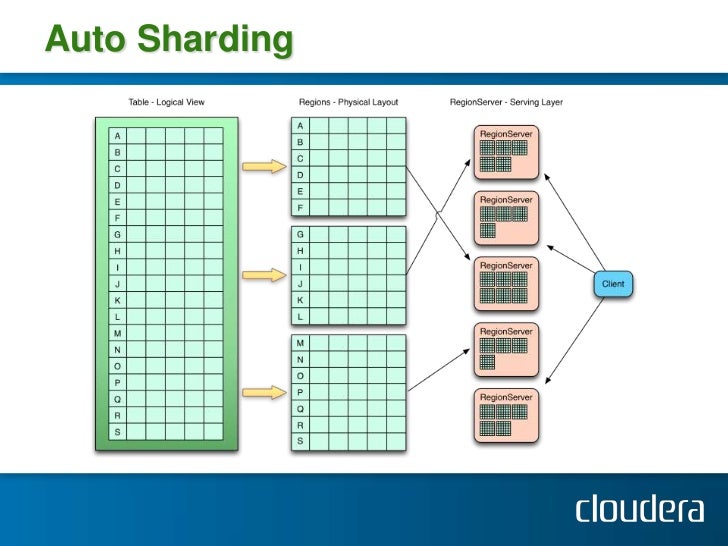
- Need of real-time random read/write on a high scale
- Variable Schema: columns can be added or removed at runtime (schema-on-read)
- Many columns of the datasets are sparse
- Key based retrieval and auto sharding is required
- Need of consistency more than availability
- Data or tables have to be denormalized for better performance
ACID
- Atomicity: An operation in HBase either completes entirely or not at all for a row, but across nodes it is eventually consistent.
- Durability: An update in HBase will not be lost due to WAL and MemStore.
- Consistency and Isolation HBase is strongly consistent for a single row level but not across levels.
Schema design
Sparse
“Sparse” means that for any given row you can have one or more columns, but each row doesn’t need to have all the same columns as other rows like it (as in a relational model)

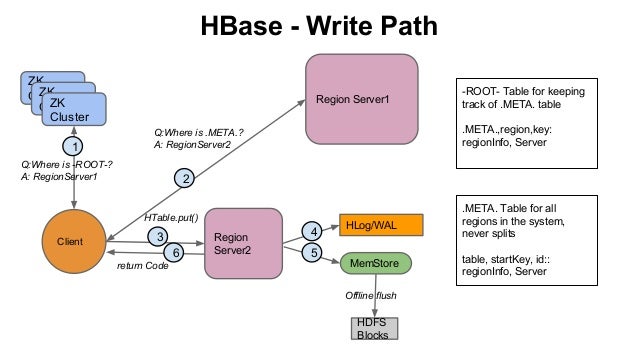
Write Path

- Client requests data to be written in HTable, the request comes to a RegionServer.
- The RegionServer writes the data first in WAL.
- The RegionServer identifies the Region which will store the data and the data will be saved in MemStore of that Region.
- MemStore holds the data in memory and does not persist it. When the threshold value reaches in the MemStore, then the data is flushed as a HFile in that region.
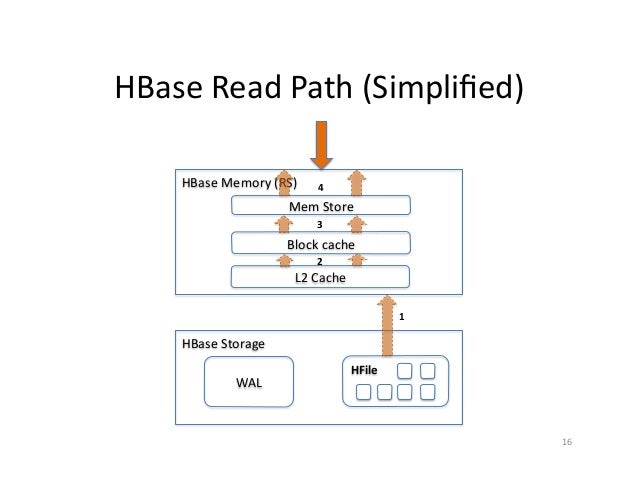
Read Path

- Client sends a read request. The request is received by the RegionServer which identifies all the Regions where the HFiles are present.
- First, the MemStore of the Region is queried; if the data is present, then the request is serviced.
- If the data is not present, the BlockCache is queried to check if it has the data; if yes, the request is serviced.
- If the data is not present in the BlockCache, then it is pulled from the Region and serviced. Now the data is cached in MemStore and BlockCache..
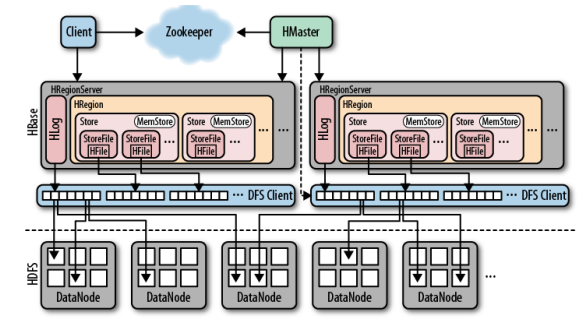
Architecture



Table
An HBase table comprises a set of metadata information and a set of key/value pairs:
- Table Info: A manifest file that describes the table “settings”, like column families, compression and encoding codecs, bloom filter types, and so on.
- Regions: The table “partitions” are called regions. Each region is responsible for handling a contiguous set of key/values, and they are defined by a start key and end key.
- WALs/MemStore: Before writing data on disk, puts are written to the Write Ahead Log (WAL) and then stored in-memory until memory pressure triggers a flush to disk. The WAL provides an easy way to recover puts not flushed to disk on failure.
- HFiles: At some point all the data is flushed to disk; an HFile is the HBase format that contains the stored key/values. HFiles are immutable but can be deleted on compaction or region deletion.

Regions

Region server


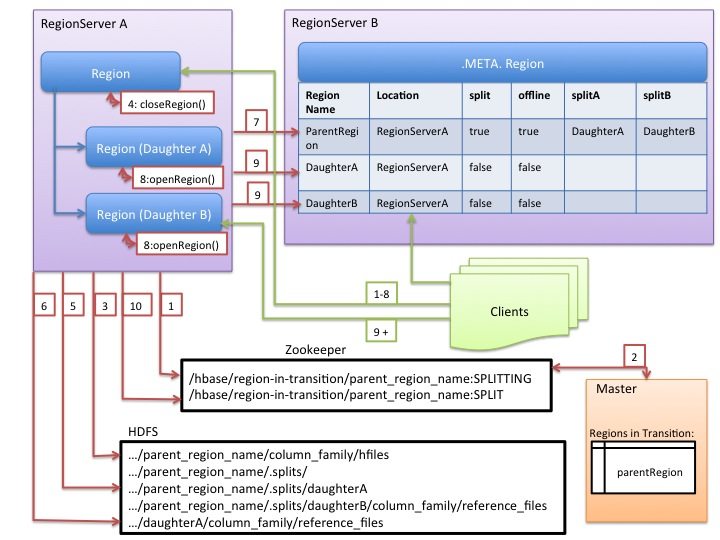
Region splitting

Region splitting process

- RegionServer decides locally to split the region, and prepares the split. As a first step, it creates a znode in zookeeper under /hbase/region-in-transition/region-name in SPLITTING state.
- The Master learns about this znode, since it has a watcher for the parent region-in-transition znode.
- RegionServer creates a sub-directory named “.splits” under the parent’s region directory in HDFS.
- RegionServer closes the parent region, forces a flush of the cache and marks the region as offline in its local data structures. At this point, client requests coming to the parent region will throw NotServingRegionException. The client will retry with some backoff.
- RegionServer create the region directories under .splits directory, for daughter regions A and B, and creates necessary data structures. Then it splits the store files, in the sense that it creates two Reference files per store file in the parent region. Those reference files will point to the parent regions files.
- RegionServer creates the actual region directory in HDFS, and moves the reference files for each daughter.
- RegionServer sends a Put request to the .META. table, and sets the parent as offline in the .META. table and adds information about daughter regions. At this point, there won’t be individual entries in .META. for the daughters. Clients will see the parent region is split if they scan .META., but won’t know about the daughters until they appear in .META.. Also, if this Put to .META. succeeds, the parent will be effectively split. If the RegionServer fails before this RPC succeeds, Master and the next region server opening the region will clean dirty state about the region split. After the .META. update, though, the region split will be rolled-forward by Master.
- RegionServer opens daughters in parallel to accept writes.
- RegionServer adds the daughters A and B to .META. together with information that it hosts the regions. After this point, clients can discover the new regions, and issue requests to the new region. Clients cache the .META. entries locally, but when they make requests to the region server or .META., their caches will be invalidated, and they will learn about the new regions from .META..
- RegionServer updates znode /hbase/region-in-transition/region-name in zookeeper to state SPLIT, so that the master can learn about it. The balancer can freely re-assign the daughter regions to other region servers if it chooses so.
- After the split, meta and HDFS will still contain references to the parent region. Those references will be removed when compactions in daughter regions rewrite the data files. Garbage collection tasks in the master periodically checks whether the daughter regions still refer to parents files. If not, the parent region will be removed.
Perfomance tuning
- Compression
- Filters
- Counters
- HBase co-processors
Snapshots
A snapshot is a set of metadata information that allows an admin to get back to a previous state of the table. A snapshot is not a copy of the table; it’s just a list of file names and doesn’t copy the data. A full snapshot restore means that you get back to the previous “table schema” and you get back your previous data losing any changes made since the snapshot was taken
- Recovery from user/application errors
- Restore/Recover from a known safe state.
- View previous snapshots and selectively merge the difference into production.
- Save a snapshot right before a major application upgrade or change.
- Auditing and/or reporting on views of data at specific time
- Capture monthly data for compliance purposes.
- Run end-of-day/month/quarter reports.
- Application testing
- Test schema or application changes on data similar to that in production from a snapshot and then throw it away. For example: take a snapshot, create a new table from the snapshot content (schema plus data), and manipulate the new table by changing the schema, adding and removing rows, and so on. (The original table, the snapshot, and the new table remain mutually independent.)
- Offloading of work
- Take a snapshot, export it to another cluster, and run your MapReduce jobs. Since the export snapshot operates at HDFS level, you don’t slow down your main HBase cluster as much as CopyTable does.

Phoenix
Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications by combining the best of both worlds:
-
The power of standard SQL and JDBC APIs with full ACID transaction capabilities
-
The flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store
Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce.
where it fits in

Architecture
Cassandra
Data nodes

(Back to top)<hr>
Read Path

Within node

(Back to top)<hr>
Write Path


(Back to top)<hr>
Partitioning and Replication

(Back to top)<hr>
Hashing / Tokens

(Back to top)<hr>
Security

(Back to top)<hr>
Graph databases
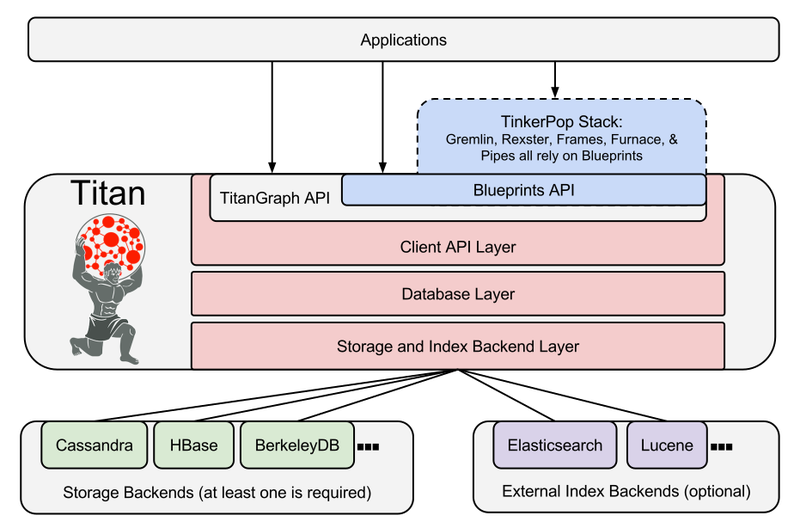
Titan
Architecture

<dependency>
<groupId>com.thinkaurelius.titan</groupId>
<artifactId>titan-core</artifactId>
<version>1.0.0</version>
</dependency>
<!-- core, all, cassandra, hbase, berkeleyje, es, lucene -->
// who is hercules' grandfather?
g.V.has('name','hercules').out('father').out('father').name
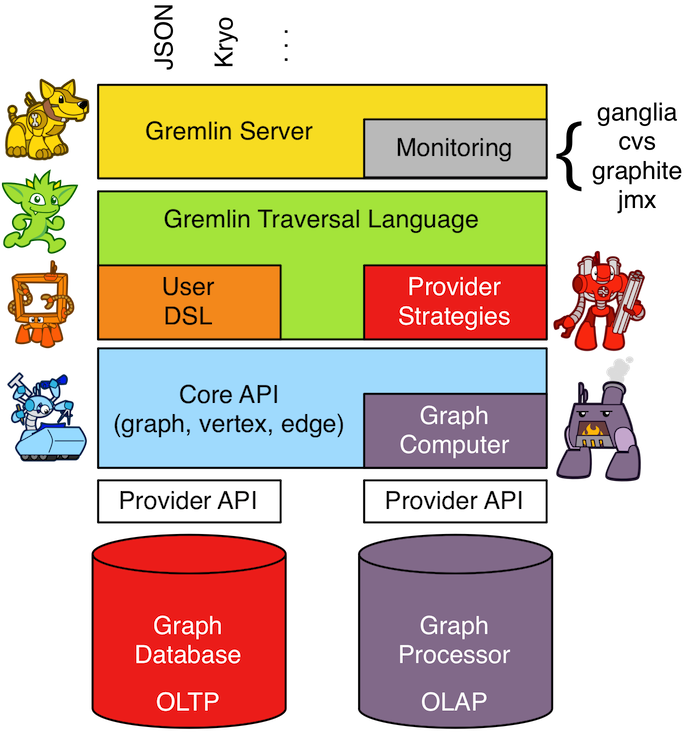
Tinkerpop
The goal of TinkerPop, as a Graph Computing Framework, is to make it easy for developers to create graph applications by providing APIs and tools that simplify their endeavors.
Architecture

Graph landscape

Getting started - Example graph

Comparisons
Cassandra vs HBase vs MongoDB vs Couchbase


Update

Cap Continuum

In this depiction, relational databases are on the line between Consistency and Availability, which means that they can fail in the event of a network failure (including a cable breaking). This is typically achieved by defining a single master server, which could itself go down, or an array of servers that simply don’t have sufficient mechanisms built in to continue functioning in the case of network partitions.
Graph databases such as Neo4J and the set of databases derived at least in part from the design of Google’s Bigtable database (such as MongoDB, HBase, Hypertable, and Redis) all are focused slightly less on Availability and more on ensuring Consistency and Partition Tolerance.
Finally, the databases derived from Amazon’s Dynamo design include Cassandra, Project Voldemort, CouchDB, and Riak. These are more focused on Availability and Partition-Tolerance.
SQL on hadoop
BigSQL
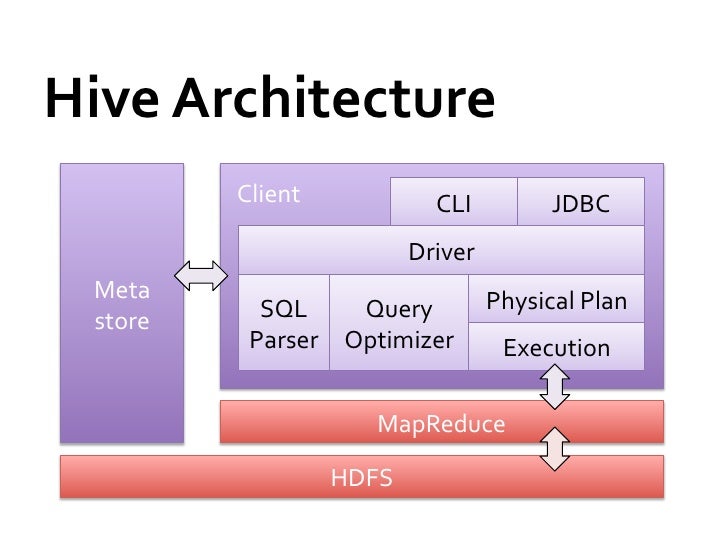
Architecture


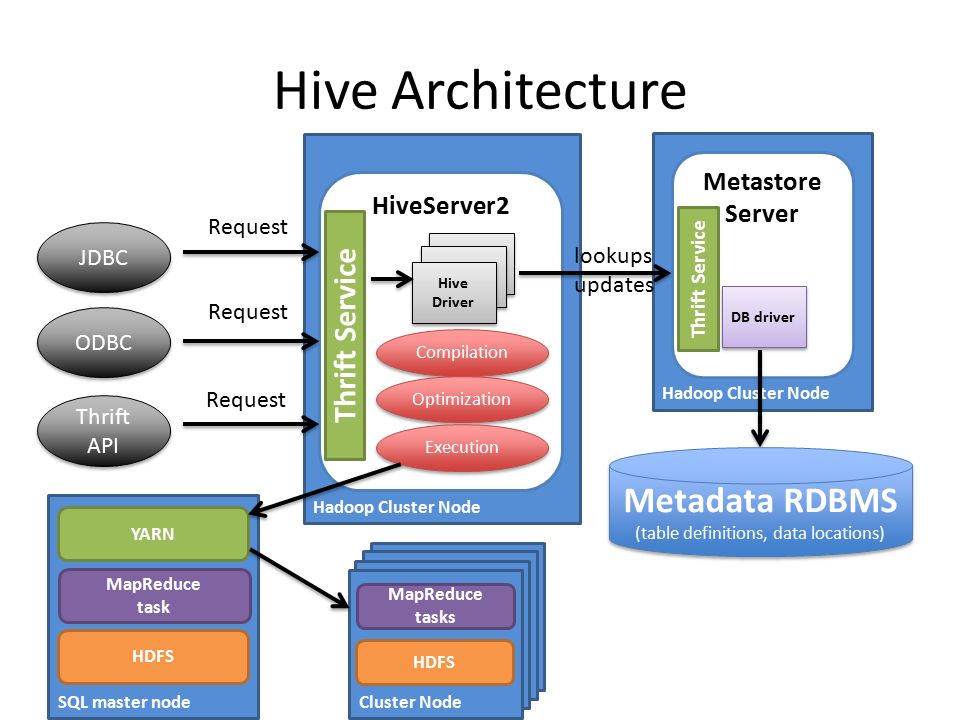
Hive


HiveQL
DDL
HCatalog
- Built on top of Hive Metastore
- Incorporates components from Hive DDL
Web Interface
Hive Web Interface
Functions:
- Schema browsing
- Detached Query execution
- No local installation
WebHCat
Functions:
- applications can make HTTP requests to access the Hive metastore
- create or queue Hive queries and commands
- Pig jobs
- MapReduce or Yarn jobs
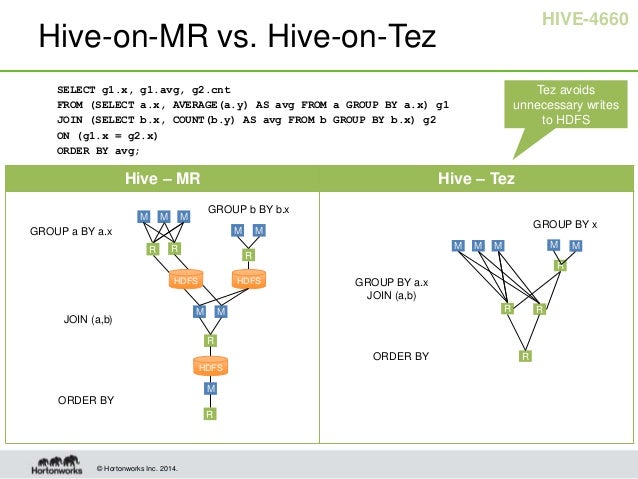
Tez
Apache Tez is part of the Stinger initiative. Tez generalizes the MapReduce paradigm to a more powerful framework based on expressing computations as a dataflow graph. Tez exists to address some of the limitations of MapReduce. For example, in a typical MapReduce, a lot of temporary data is stored (such as each mapper’s output, which is a disk I/O), which is an overhead. In the case of Tez, this disk I/O of temporary data is saved, thereby resulting in higher performance compared to the MapReduce model.
Tez is a framework for purpose-built tools such as Hive and Pig.



Tez vs Spark
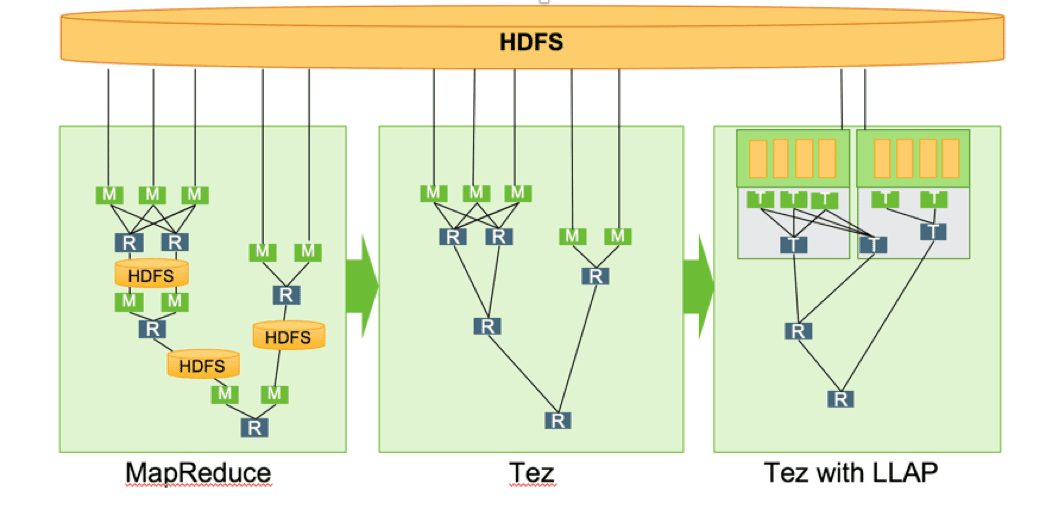
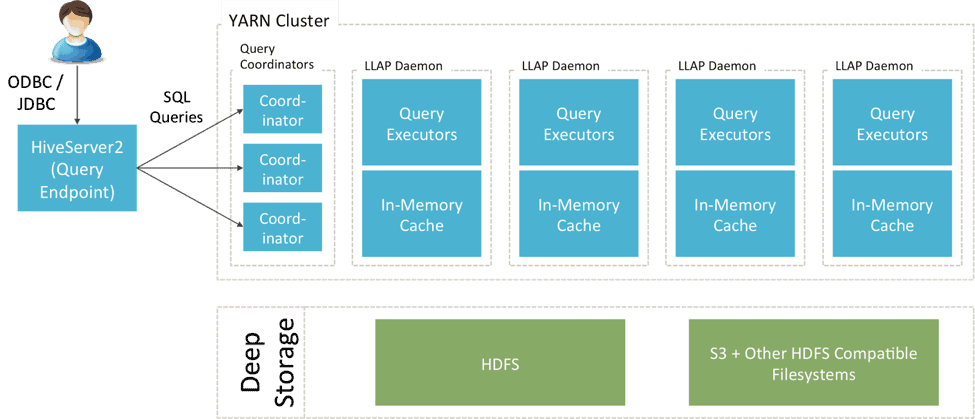
Hive with LLAP (Live Long and Process)
With 2.1 Hive introduces LLAP, a daemon layer for sub-second queries. LLAP combines persistent query servers and optimized in-memory caching that allows Hive to launch queries instantly and avoids unnecessary disk I/O. For more information see http://hortonworks.com/blog/announcing-apache-hive-2-1-25x-faster-queries-much/.

MapReduce vs Tez vs Tez LLAP
Tez LLAP process compared to Tez execution process and MapReduce process
 image source
image source
Drill
- not tied into Hadoop
- more flexible query & execution layer
- still in incubation
Impala
- dependent on Hadoop
- dependent on Hive Metastore
- rumour to not fall back to disk when memory exceeded
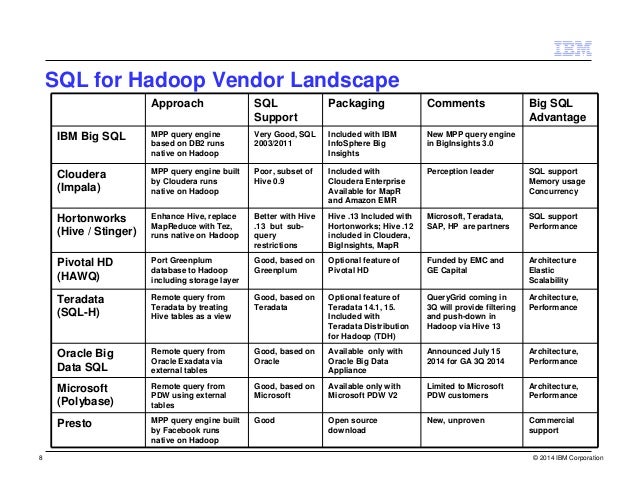
Comparison
Impala, Hive, Stinger, Pivotal, Teradata, Presto

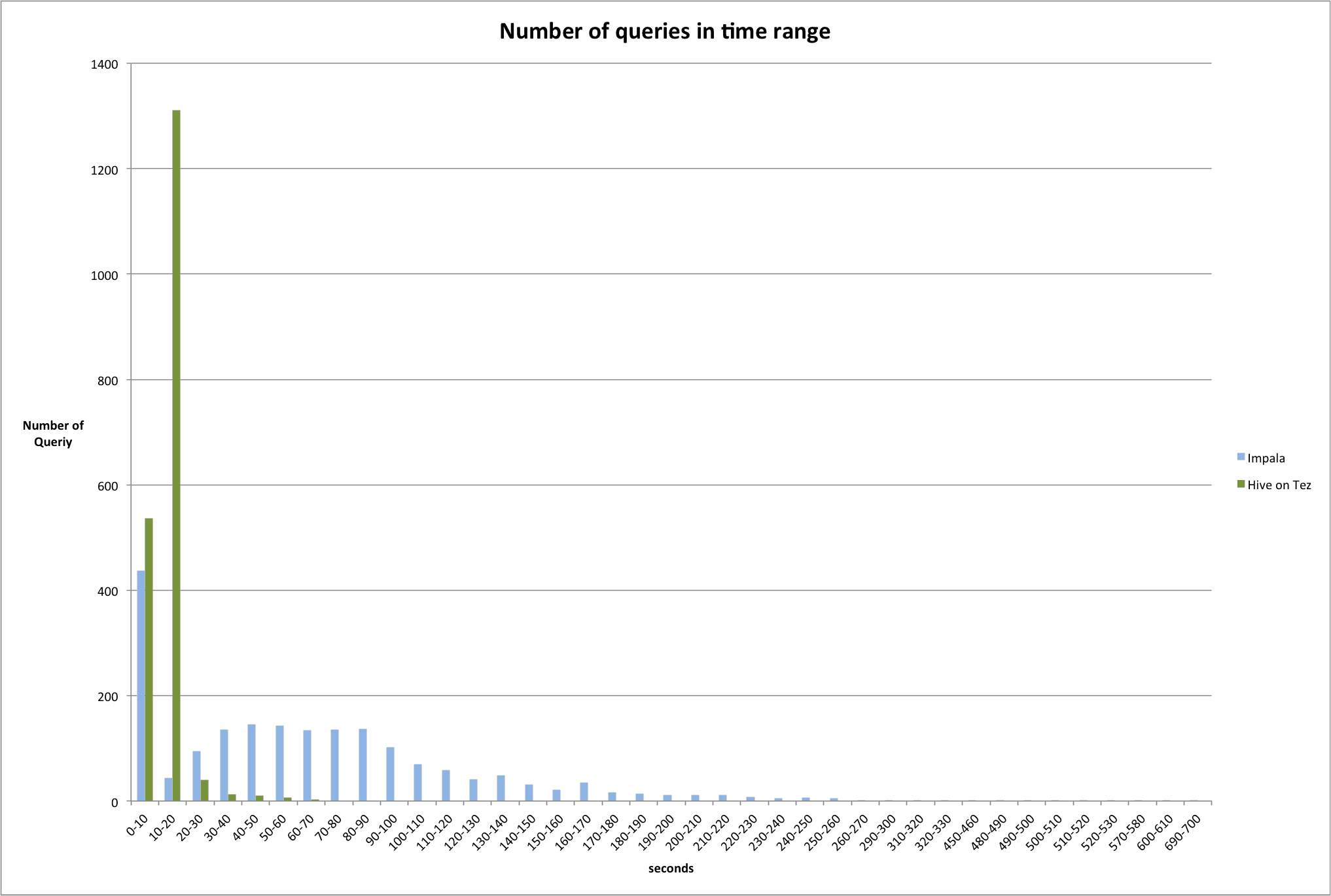
Benchmark: Impala, Hive, Spark

Benchmark: Impala, Hive-on-Tez

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Overview

{kind=link}